Abstract
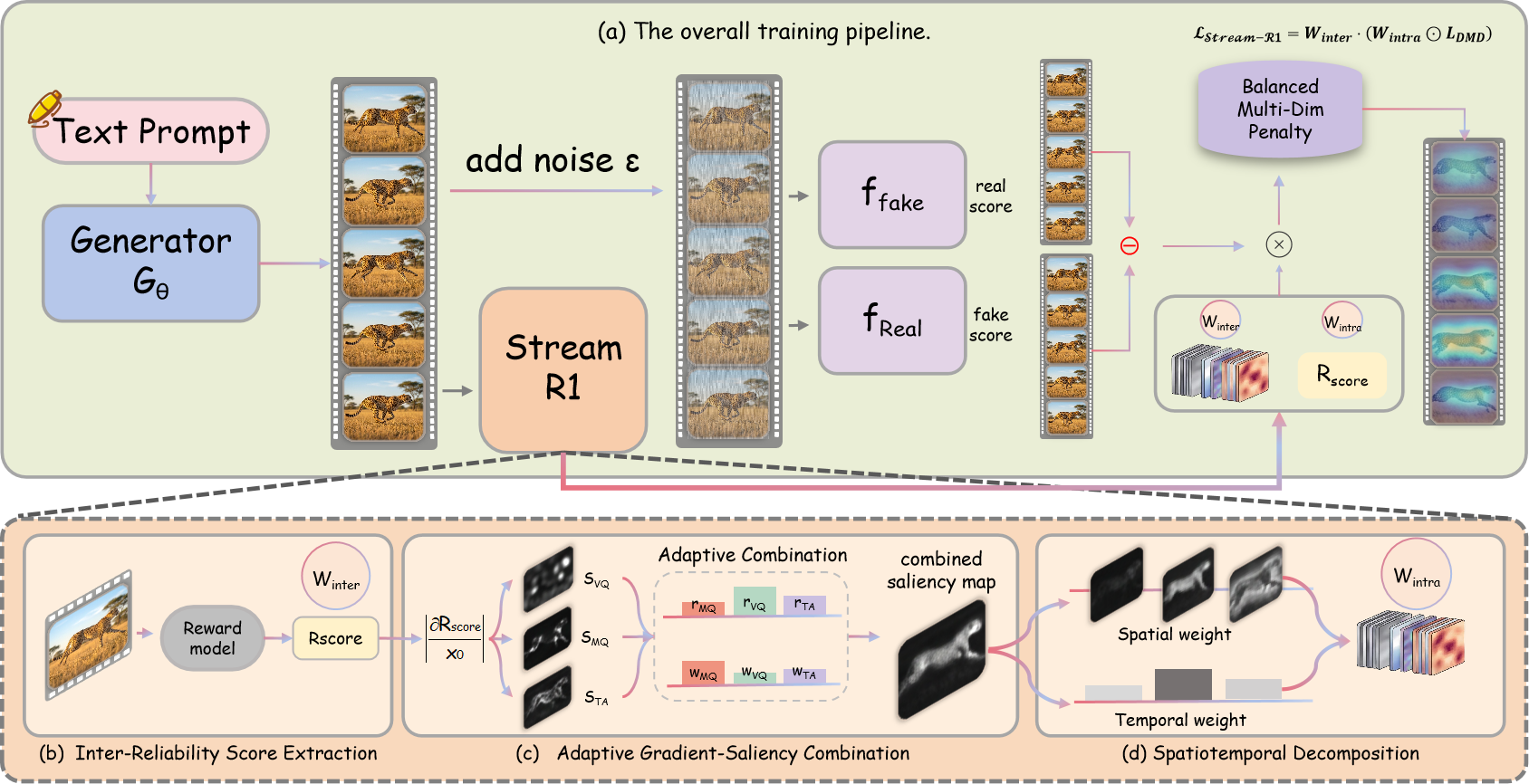
Stream-R1 reweights distribution-matching distillation along two
complementary axes — Inter-Reliability across rollouts
and Intra-Perplexity across spatiotemporal regions —
using a single shared video reward model.
Existing DMD methods for streaming video diffusion treat every
rollout, frame, and pixel as equally reliable supervision. We argue
this caps the upper bound of distilled quality, because it overlooks
two complementary axes of variance in the DMD signal. Stream-R1
rescales each rollout’s loss by an exponential of a pretrained
reward score — rollouts whose gradient genuinely points toward
the teacher’s high-quality mode dominate — and
back-propagates the same reward model to obtain per-pixel saliency
that concentrates optimization where the local reward landscape has
not yet flattened. An adaptive balancing mechanism keeps visual
quality, motion quality, and text alignment improving in lockstep.
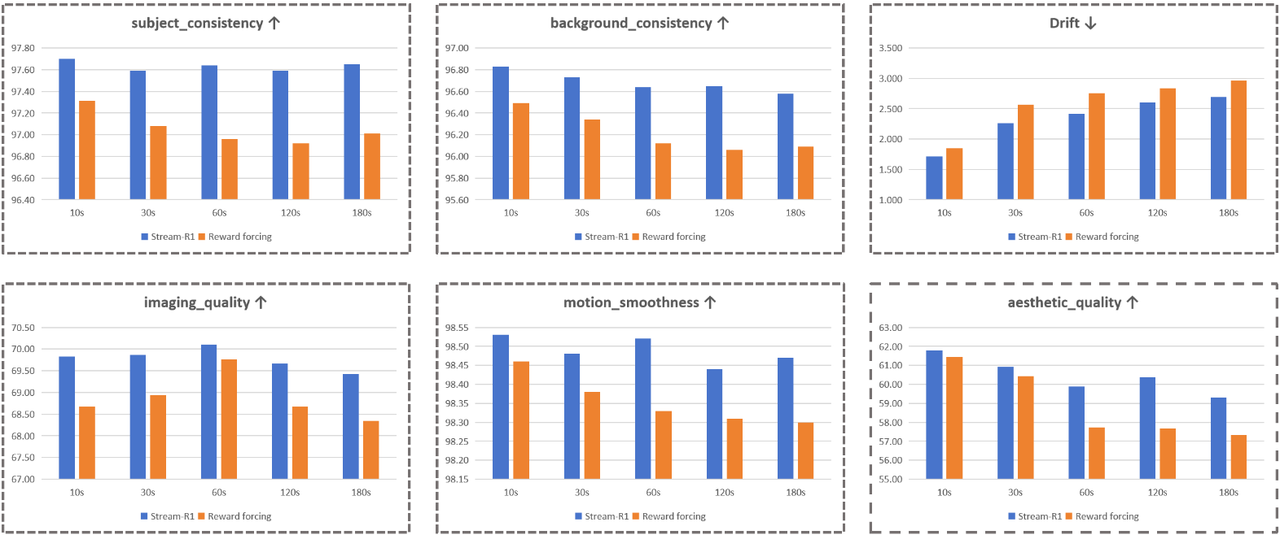
The resulting student surpasses its multi-step Wan2.1 teacher on
VBench Total and Semantic at 23.1 FPS, with no
architectural change and zero inference overhead.
01
Inter-Reliability Weighting
The DMD gradient
g = ffake − freal varies
in reliability across rollouts. Stream-R1 rescales each rollout’s
loss by exp(β · rfinal), so
rollouts whose gradient genuinely points toward the teacher’s
high-quality mode dominate the supervision.
02
Intra-Perplexity Weighting
Back-propagating the reward model yields a per-pixel saliency
volume S ∈ RF×H×W;
factorized into spatial and temporal weights, it concentrates
optimization where further refinement yields the largest expected
gain — regions whose local reward landscape has not yet
flattened.
03
Adaptive Reward Balancing
A sliding window tracks per-axis (Visual / Motion / Text-align)
improvement and softly down-weights axes that are already
improving, keeping all three quality dimensions advancing
together.